
Most enterprises assume that deploying automation automatically delivers efficiency, but the reality is more nuanced. Without deliberate system design, edge cases and process variance quietly drain resources, erode quality, and stall the very growth automation was meant to generate. Real scalability requires more than connecting tools. It demands a structured architecture where AI, orchestration, feedback loops, and human oversight work as a unified system. This guide breaks down the five layers of modern scalable automation, quantifies real-world impact with verified data, and maps actionable strategies your operations team can apply starting today.
Table of Contents
- The layered architecture of scalable automation systems
- How AI and automation transform enterprise outcomes
- Managing edge cases and why scalability matters
- Key challenges and practical strategies for scalable automation
- Our take: What most leaders miss about scalable automation
- Next steps: Empower your enterprise with scalable automation
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Layered automation framework | Enterprises achieve scalable automation by implementing layered architectures with intelligence, orchestration, feedback, execution, and monitoring. |
| AI boosts business outcomes | AI-driven automation reduces costs, increases speed, and lifts revenue and quality when deployed in targeted processes. |
| Edge case management crucial | Exception handling and human oversight prevent resource drain and ensure scalable automation performs reliably. |
| Solve scalability challenges early | Address issues like data drift, system coordination, and governance before scaling to avoid operational bottlenecks. |
| Hybrid models outperform | Combining AI with human-in-the-loop delivers superior performance compared to purely autonomous systems in most enterprise contexts. |
The layered architecture of scalable automation systems
Automation done right is not a single workflow. It is a stack of interdependent layers, each serving a specific function and supporting the others. Scalable automation systems in enterprises typically consist of five distinct architectural layers: Intelligence (AI and ML models for decision-making), Orchestration (business logic and sequencing), Learning (feedback loops for continuous improvement), Execution (tool integrations and action triggers), and Monitoring (real-time oversight and alerting).
Each layer handles a discrete responsibility. The Intelligence layer processes inputs and generates decisions. The Orchestration layer sequences and routes those decisions through business logic. The Learning layer ingests outcomes and refines future behavior. The Execution layer connects to your existing tools and takes action. The Monitoring layer tracks performance, flags anomalies, and closes the loop.
Building a strong scalable automation strategy means understanding how these layers interact. When any one layer is weak or missing, the entire system degrades. A well-designed automation system design ensures that each layer is explicitly built, not assumed.
Here is a direct comparison between traditional automation approaches and a fully layered architecture:
| Feature | Traditional automation | Layered automation |
|---|---|---|
| Decision-making | Rule-based, static | AI-driven, adaptive |
| Error handling | Manual review required | Built-in exception routing |
| Scalability | Limited by hardcoded logic | Designed for distributed growth |
| Learning capability | None | Continuous feedback loops |
| Monitoring | Reactive, post-failure | Proactive, real-time |
| Integration flexibility | Rigid, point-to-point | Modular, API-first |
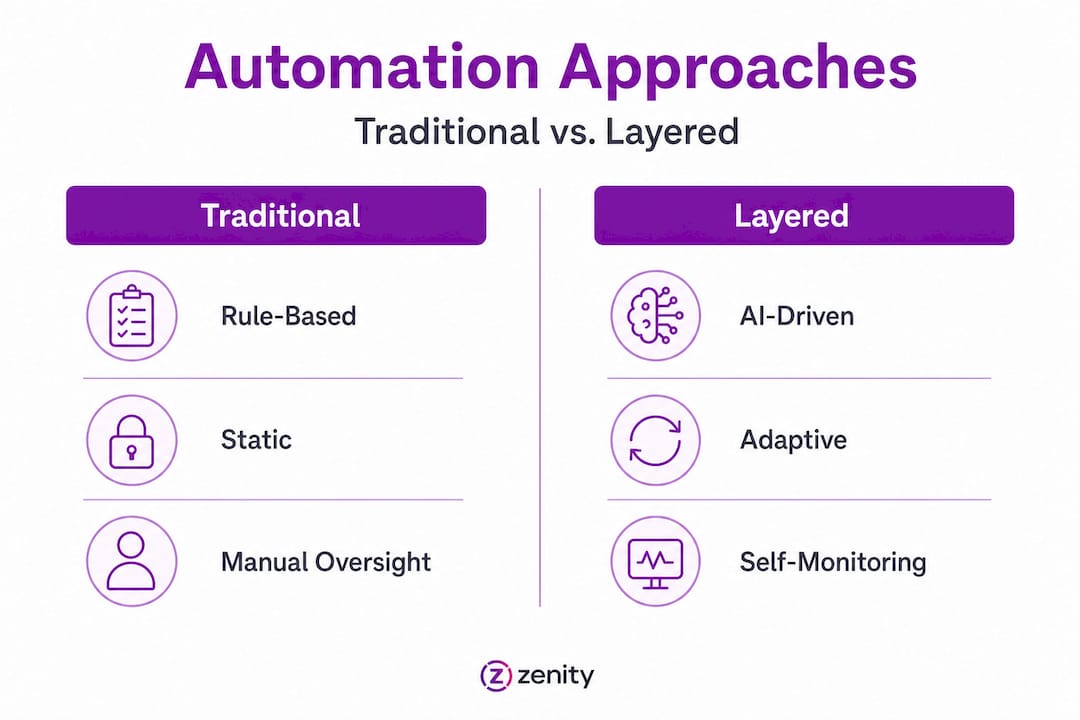
The difference is not cosmetic. Traditional automation breaks at scale because it cannot adapt. A layered architecture, by contrast, is built for real-world complexity, as detailed in this scalable product development guide.
Key business advantages of the layered approach:
- Faster incident recovery because the Monitoring layer isolates failures before they cascade
- Lower maintenance costs because the Learning layer reduces the need for manual rule updates
- Greater team agility because each layer can be updated independently without rewriting the full system
- Stronger compliance and auditability because the Orchestration layer creates a clear record of every decision path
- Improved vendor flexibility because the Execution layer uses modular integrations rather than locked-in tools
This architecture is not theoretical. It is the proven foundation behind the most resilient enterprise automation systems operating at scale today.
How AI and automation transform enterprise outcomes

Now that we see the structure, let's explore the quantifiable business value enabled by scalable automation systems. The numbers are not abstractions. They represent real operational shifts in cost, speed, and quality that directly affect your bottom line.
Consider what AUDI achieved using AWS Karpenter for scalable Kubernetes automation in their car-configurator platform: a 63% reduction in compute costs and a 20% improvement in application startup time. That is not a marginal gain. It is a structural cost advantage that compounds over time.
At the workflow level, the data is even more striking. A controlled workflow automation study showed a 151x reduction in execution time, compressing a 185-second manual process down to 1.23 seconds with zero errors, compared to a 5% manual error rate. In high-volume operations, a 5% error rate translates to thousands of compounding failures per day.
Agentic AI in pharma delivered measurable commercial value too, with a 1 to 2% revenue increase in sales pre-call planning, a 5 to 20% reduction in content production costs, and launch timelines compressed to 1 to 2 weeks. These are not pilot metrics. They reflect production-scale AI automation operating inside real enterprise workflows.
| Enterprise | Automation type | Key result |
|---|---|---|
| AUDI | Kubernetes compute automation | 63% cost reduction, 20% faster startup |
| Pharma (McKinsey) | Agentic AI for sales and content | 1-2% revenue lift, 5-20% cost savings |
| Workflow study | Process automation benchmark | 151x speed increase, 0% error rate |
Understanding where scalable AI automation delivers the highest returns helps you prioritize deployment. The areas showing the greatest consistent impact are:
- Sales and pre-call planning: AI agents that research, personalize, and sequence outreach at scale
- Content production: Automated drafting, approval routing, and publishing with brand compliance checks
- Operations and logistics: Workflow routing, exception flagging, and real-time status tracking
- Finance and compliance: Automated reconciliation, audit trails, and anomaly detection
- Customer support: AI-driven triage, escalation routing, and resolution tracking
The key to AI-driven process automation that actually delivers these results is matching the right layer to the right process. Not every function needs all five layers at full depth. But high-volume, decision-dense workflows almost always benefit from the full stack.
Pro Tip: Start with your highest-volume, lowest-risk processes. These give you clean data, fast feedback cycles, and proof of value without exposing the business to significant failure risk. Once the Learning layer has data to work with, scaling to complex workflows becomes far more predictable.
The evidence consistently shows that automation is not a cost center when deployed correctly. It is a structural competitive advantage. The challenge is building systems that hold together as complexity grows, which brings us to the critical question of edge cases.
Managing edge cases and why scalability matters
While the numbers are impressive, scaling automation requires confronting the complexity of edge cases and operational variance. An edge case is any input or situation that falls outside the standard process path. Most automation systems are designed for the "happy path," the ideal sequence where every input is clean and every step completes as expected.
The real world does not operate on the happy path. Edge cases represent 20% of operations but consume a disproportionate share of resources. They require exception handling logic, human-in-the-loop escalation paths, and thorough testing from the very first day of deployment.
"The automation systems that scale successfully are not the ones with the most advanced AI. They are the ones built to fail gracefully, with clear escalation paths and exception handling baked into the architecture from the start."
The 7 key automation system components that support workflow efficiency all include some form of exception handling logic. It is not optional. It is structural. And system integration types matter too because poorly integrated systems create new edge cases at every connection point.
Here are the exception handling strategies that enterprise systems rely on to stay stable under real-world conditions:
- Explicit fallback rules: Define what the system does when a standard path fails, before that failure happens
- Confidence thresholds: Set minimum AI confidence scores below which a human reviewer is automatically triggered
- Audit logging at every step: Capture inputs, decisions, and outputs so edge case patterns can be identified and resolved over time
- Canary deployments: Release automation updates to a small subset of traffic first to catch edge cases before they affect the full operation
- Feedback queues: Route unresolved edge cases into a structured review queue rather than letting them silently fail
- Regular stress testing: Simulate abnormal inputs and failure scenarios on a scheduled basis, not just at launch
BCG research on scaling AI with new processes reinforces that technology alone does not solve the edge case problem. Governance structures, decision authorities, and escalation protocols are what actually keep scaled automation stable.
Pro Tip: Invest in human-in-the-loop oversight and governance frameworks before you need them. Teams that wait until edge cases become operational crises spend far more time and budget on recovery than teams that build these safeguards into the architecture upfront.
Treating edge cases as an afterthought is one of the most common and costly mistakes in enterprise automation. Treating them as first-class design requirements is what separates pilots that scale from pilots that stall.
Key challenges and practical strategies for scalable automation
With edge cases in mind, let's examine the ongoing challenges every enterprise faces when scaling automation and how to address them proactively. These are not temporary friction points. They are structural realities that require deliberate management.
Scalability challenges in production automation systems include data drift (when the data the model was trained on no longer reflects current reality), model degradation (when AI performance erodes over time without retraining), distributed system coordination (when multiple automated systems must act in sync across departments or geographies), and the persistent tradeoff between scalability and maintainability.
Data drift is particularly damaging because it is invisible until performance drops. A model trained on last year's customer behavior may produce increasingly poor decisions this year without triggering any obvious alert. MLOps practices, including scheduled retraining and performance benchmarking, are the primary defense.
Here are the practical strategies we recommend for enterprise leaders managing scalable automation:
- Adopt hybrid human-AI models from day one. Fully autonomous systems perform well under normal conditions and fail unpredictably under edge conditions. Hybrid models with defined escalation points are more reliable and easier to audit.
- Implement MLOps pipelines for continuous model management. This includes version control for models, automated performance monitoring, scheduled retraining cycles, and rollback capabilities when a new model underperforms.
- Establish centralized governance early. Assign clear ownership for each layer of the automation stack, define decision authority for changes, and create a change management process that prevents ad hoc modifications from destabilizing live systems.
- Build in interoperability standards. Systems that cannot communicate cleanly create manual handoff points that defeat the purpose of automation. API-first integrations and standardized data schemas reduce coordination overhead as systems scale.
- Measure operational maturity, not just technical performance. Automation maturity is as much about process discipline and team capability as it is about software. Assess both dimensions regularly.
When evaluating build versus buy decisions for your automation stack, consider these trade-offs:
- Build: Offers full customization and no vendor lock-in, but requires significant internal engineering capacity and longer deployment timelines
- Buy (off-the-shelf tools): Faster deployment and lower initial cost, but may not support the specific workflows or scale requirements of your enterprise
- Hybrid approach: Combine verified third-party tools for standard functions with custom development for differentiated workflows. This is the approach we consistently see deliver the best outcomes.
Comparing your automation tools features against your actual operational requirements before committing to a stack is essential. And following a structured automation deployment guide keeps the rollout predictable and measurable.
Research from BCG on scaling AI strategies and real-world analysis of autonomous warehouse operations both confirm the same conclusion: organizations that invest in process maturity alongside technology selection scale faster and with fewer costly setbacks.
Our take: What most leaders miss about scalable automation
Having outlined the practical strategies, here is a candid perspective that reframes how leaders should approach scalable automation for lasting growth.
The most common failure we see is not technical. It is architectural overconfidence. Leaders invest in advanced AI, deploy impressive pilots, and then attempt to scale quickly. The pilot worked because conditions were controlled. At scale, the conditions are not controlled. That is where fully autonomous systems break down.
Fully autonomous automation fails in real-world environments because real-world environments are inherently unpredictable. Process variance, data quality issues, and organizational change all create conditions the original model was never trained to handle. The leaders who succeed at scale build hybrid systems with explicit human escalation paths, not because they distrust AI, but because they understand its boundaries.
The second misconception is that pilot success predicts scale success. It rarely does. Pilots almost never test for edge complexity, data drift, or cross-department coordination failures. They test for the happy path. Investing in governance, exception handling, and automation system fundamentals before a pilot completes is what creates the foundation for real scale.
The uncomfortable truth is this: culture and process adaptation are harder than technology selection, and they matter more. An organization that cannot adapt its workflows, roles, and decision-making processes to support automation will fail to scale regardless of which tools it buys. The technology is often the easy part.
Pro Tip: Before expanding automation to new departments, run an operational readiness assessment. Evaluate whether the team understands escalation paths, whether data quality meets model requirements, and whether governance ownership is clearly assigned. Technology scales. Process gaps do not resolve themselves.
Next steps: Empower your enterprise with scalable automation
For leaders ready to act, here is how you can leverage proven tools to drive scalable automation in your enterprise.
Building a scalable automation system requires more than good intentions. It requires verified blueprints, tested tools, and a structured deployment path. At Starks Global Group, we have done the groundwork so your team does not start from zero.

Explore our automation tools marketplace to find verified AI tools mapped to specific workflow layers. Access the AI chatbot sales system blueprint to see how a production-grade automation architecture is structured from Intelligence layer to Monitoring. And visit the Starks Global Group platform to explore the full library of scalable automation architectures, deployment guides, and infrastructure blueprints built for enterprise growth. Every tool and blueprint we recommend has been tested and validated. You get structure, not just suggestions.
Frequently asked questions
What are the five layers of scalable automation systems?
They are Intelligence (AI and ML), Orchestration, Learning, Execution, and Monitoring, with each layer handling decision-making, process logic, feedback, actions, and oversight respectively, as defined in enterprise automation architecture research.
How does automation reduce errors and speed up processes?
Automation enables a 151x execution time reduction by standardizing workflows and using AI to monitor outcomes, compressing a 185-second manual process to 1.23 seconds with zero errors versus a 5% manual error rate.
Why do edge cases impact scalability?
Edge cases consume disproportionate resources and require custom handling or human oversight, so scalable systems prioritize exception testing and governance from the very first deployment stage.
What are the biggest challenges in scaling automation?
Data drift, model degradation, distributed system coordination, and the balance between scalability and maintainability are the four core challenges that enterprise automation teams must plan for explicitly.
What is the best first step for scalable automation in enterprises?
Begin with high-volume, low-risk processes and ensure human-in-the-loop oversight for edge cases, which gives your Learning layer clean feedback data and your governance framework a real foundation to build on.