
Growing organizations often reach a breaking point where manual processes, disconnected tools, and reactive workflows actively limit performance. Operational inefficiencies compound quickly at scale, producing delays, inconsistencies, and rising overhead that no single software purchase can solve. Building a structured, layered automation infrastructure is the only reliable path to deploying AI-driven systems that hold up under real business pressure. This guide walks you through each phase of that build, from architectural foundations to validation, so you can move from fragmented operations to a scalable, verified automation stack that actually delivers results.
Table of Contents
- Understand the layered architecture of automation infrastructure
- List your prerequisites: Tools, skills, and planning
- Step-by-step guide: Building your automation infrastructure
- Troubleshooting and common mistakes to avoid
- Validating your infrastructure: How to measure success
- Our perspective: What most guides miss about automation infrastructure
- Connect with advanced automation solutions
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Layered architecture clarity | Understanding each layer of AI automation infrastructure helps ensure scalable and stable systems. |
| Prepare with the right tools | Gathering appropriate tools and aligning business and technical goals is crucial before building. |
| Stepwise execution | Follow a structured sequence for deploying and integrating automation infrastructure. |
| Anticipate troubleshooting needs | Prevent common pitfalls by planning for ownership maps, rollback rules, and observability early. |
| Measuring success | Post-deployment validation using metrics and KPIs is key to demonstrating operational impact. |
Understand the layered architecture of automation infrastructure
With the operational challenge established, let's break down how a layered automation infrastructure addresses those needs.
Most organizations treat automation as a collection of standalone tools. That approach creates fragile, unmanageable systems that break under load and resist scaling. The better model treats your entire stack as a connected architecture, where every component sits in a defined layer and serves a specific function.
According to a detailed system architecture guide, AI infrastructure follows four layers: infrastructure foundation, model serving, application services, and client integration. Each layer builds on the one below it, and failures in lower layers propagate upward if not properly isolated.
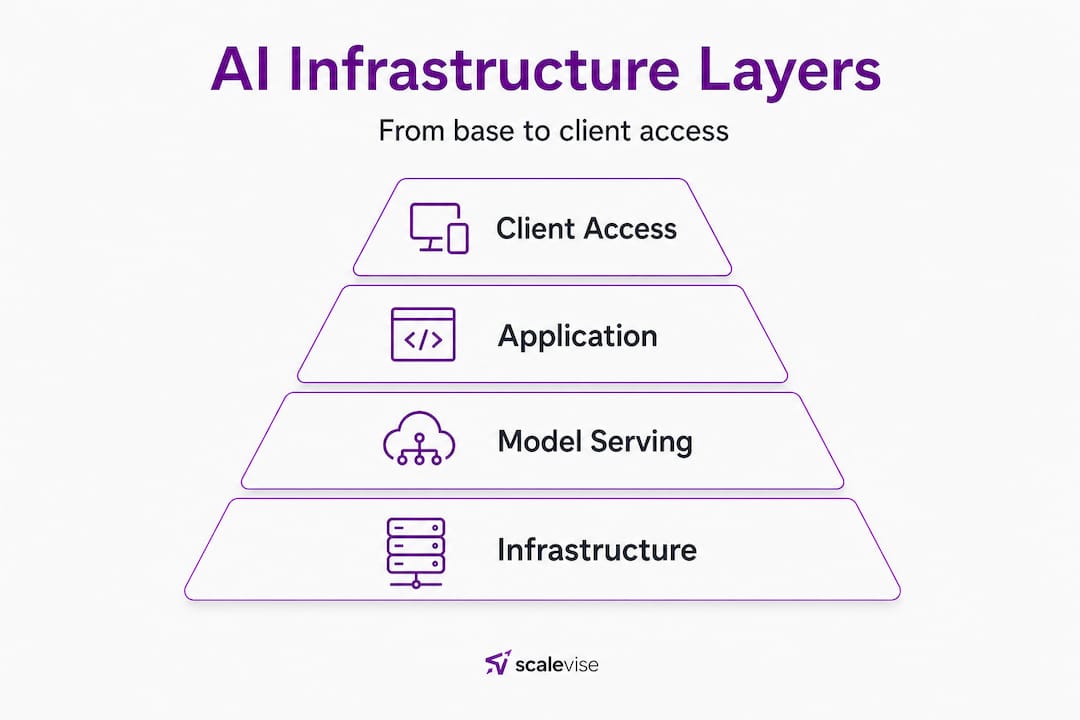
Here is what each layer contains and why it matters:
| Layer | Components | Primary function |
|---|---|---|
| Infrastructure foundation | Docker, storage, networking | Stable compute and data access |
| Model serving | LLMs, embeddings, vector DBs | AI processing and retrieval |
| Application services | Chat, RAG, orchestration | Business logic and automation flows |
| Client integration | APIs, SDKs, web endpoints | User-facing access and outputs |
The infrastructure foundation handles compute, containerization, and storage. Containers (typically Docker) ensure consistent environments across development, staging, and production. Storage solutions manage both structured data for business logic and unstructured data for AI model inputs.

The model serving layer is where your AI capabilities live. This includes large language models (LLMs), vector databases for semantic search, and embedding pipelines that convert raw content into formats your models can process.
Application services sit above the model layer and include retrieval-augmented generation (RAG) pipelines, orchestration tools that coordinate multi-step workflows, and business-specific logic. This is the layer most directly connected to your infrastructure automation build and where the majority of your workflow customization happens.
Client integration is the final layer, handling all external-facing access points including APIs, user interfaces, and third-party platform connections.
Key takeaway: A layered architecture is not optional for scalable AI. It is the structural requirement that separates systems that survive growth from those that collapse under it.
List your prerequisites: Tools, skills, and planning
Knowing the layers, it is crucial to gather supporting tools and resources before you start the build.
Preparation is where most infrastructure projects succeed or fail. Attempting to build without verified tools, skilled team members, and aligned business requirements produces waste and rework. The following checklist covers what you need before writing a single line of deployment configuration.
Core tools you need:
- Containerization: Docker for packaging models and services into portable, consistent units
- CI/CD pipelines: Automated workflows that handle data validation and deployment stages including model training, testing, registry promotion, and containerized deployment to services like ECS
- Storage systems: Object storage, relational databases, and vector databases matched to your data types
- Monitoring stack: Prometheus for metrics collection and Grafana for visualization and alerting
- Orchestration tools: Platforms that coordinate multi-step workflows across your application services layer
Skills required across your team:
| Role | Core skills | What they own |
|---|---|---|
| DevOps engineer | Docker, CI/CD, networking | Infrastructure foundation |
| ML engineer | Model training, evaluation, embeddings | Model serving layer |
| Systems integrator | API design, data pipelines | Application and client layers |
| Data engineer | Pipeline design, embedding datasets | Data preparation and quality |
Planning alignment checklist:
Before starting the build, your team should be able to answer the following clearly:
- What specific business processes are being automated and what is the expected outcome?
- Which AI models will serve those processes and have they been evaluated for accuracy and cost?
- What are the data sources, and have data quality standards been established?
- What is the deployment environment and what are the security and compliance requirements?
Pro Tip: Document your business goals and map them directly to technical components before you finalize your tool choices. Misalignment between business requirements and technical design is the single most common reason automation projects stall after the initial build.
Your structured automation guide provides an additional framework for aligning goals with system design before you proceed to the build phase.
Step-by-step guide: Building your automation infrastructure
With preparations complete, here is how to execute the infrastructure build for maximum reliability and scalability.
The build phase follows a sequential process. Skipping steps or executing them out of order creates dependency failures and makes troubleshooting significantly harder. Follow this order:
-
Set up your infrastructure foundation. Deploy Docker on your target environment. Configure networking, establish access controls, and provision your storage systems. This layer must be stable and tested before you add anything on top of it.
-
Establish your CI/CD pipeline. Your pipeline is the operational backbone of your entire stack. Structure it with discrete stages: data validation, model training, automated testing, model registry promotion, and deployment. The MLOps CI/CD model provides a production-grade template for these stages, including containerized deployment and integrated monitoring.
-
Deploy your model serving layer. Container your chosen LLMs and embedding models using Docker. Connect your vector database for semantic retrieval. Run smoke tests on model endpoints to verify inference response times and accuracy before connecting any application services.
-
Build your data pipelines. Data pipelines feed your models and application services. Define ingestion, transformation, and validation rules. A broken pipeline that silently passes corrupt data is harder to diagnose than a pipeline that fails loudly, so build validation checkpoints at each stage.
-
Configure application services. Deploy your orchestration layer and connect it to your model serving layer. Build your RAG pipeline if semantic retrieval is part of your use case. Configure business logic and workflow triggers that define how automation runs in response to events or schedules.
-
Integrate client endpoints. Expose your application services through well-documented APIs or user-facing interfaces. Apply authentication, rate limiting, and logging at this layer to ensure every interaction is traceable.
-
Activate monitoring across all layers. Connect Prometheus to your infrastructure, model serving, and application services layers. Build Grafana dashboards that surface key metrics for each layer, including model latency, pipeline error rates, and deployment health.
"A well-structured CI/CD pipeline with containerized deployment and monitoring is not a feature, it is the foundation that makes every other component of your automation infrastructure trustworthy."
Pro Tip: Do not wait until all layers are complete before running tests. Test each layer as you build it, and run integration tests between layers before moving to the next. This practice, called incremental integration testing, dramatically reduces the time spent diagnosing failures after full deployment.
For a deeper look at automation system design principles, and to understand how enterprise process automation applies these patterns at scale, explore those resources before finalizing your architecture.
Troubleshooting and common mistakes to avoid
After building, it is essential to understand the most common stumbling blocks and how to address them quickly.
Even well-planned infrastructure projects encounter operational issues after deployment. The difference between teams that recover quickly and those that spend days diagnosing problems comes down to preparation. Most recovery failures are not caused by the incident itself. They are caused by documentation and process gaps that make diagnosis slow and inconsistent.
A widely recognized analysis of MLOps operational runbooks identified critical gaps that consistently slow recovery. These gaps include missing incident classification (distinguishing serving issues from quality degradation or deployment failures), undefined ownership maps, no definition of a "known good state," skipped feature lineage checks, and a complete absence of rollback rules.
The most common mistakes in automation infrastructure builds:
- No incident classification system. When something breaks, your team needs to know immediately whether the issue is at the infrastructure layer, model serving layer, or application layer. Without classification, every incident triggers a full-system investigation instead of a targeted response.
- Missing ownership maps. Every component in your stack should have a defined owner. Ambiguity about who is responsible for a given layer or service guarantees slower recovery times and finger-pointing during incidents.
- Undefined rollback rules. Before you deploy to production, you must define exactly what conditions trigger a rollback and exactly how that rollback is executed. This is non-negotiable for any production-grade automation system.
- Incomplete observability. Monitoring dashboards that only surface uptime metrics are not sufficient. You need visibility into model output quality, data pipeline health, and workflow execution success rates, not just whether your containers are running.
- Skipped feature lineage checks. When model outputs degrade, the cause is often an upstream data change. Feature lineage tracking documents where your model inputs come from and flags when those sources change, giving you a direct path to root cause analysis.
Pro Tip: Build your incident classification and rollback rules into your runbook before your first production deployment. Treat these documents as part of your infrastructure, not optional reference material.
For a detailed breakdown of workflow components and how they connect to your observability strategy, that resource provides concrete implementation guidance.
"The infrastructure that fails gracefully and recovers predictably is more valuable than the infrastructure that never fails. Build for recovery, not just for uptime."
Validating your infrastructure: How to measure success
Once your infrastructure is running, measuring outcomes is critical to prove value and guide future improvements.
Deployment is not the finish line. A completed build without systematic validation is an untested assumption. Your validation process must cover both technical performance and business impact, because infrastructure that is technically stable but operationally irrelevant has failed its core purpose.
Technical validation metrics to track:
- Model inference latency (average and p99 response times)
- Pipeline error rates and data validation failure frequency
- Deployment success rate across CI/CD stages
- Container restart frequency and infrastructure uptime
- Rollback frequency and mean time to recovery (MTTR)
Business-aligned KPIs to measure:
| Metric | Pre-automation baseline | Post-automation target | How to measure |
|---|---|---|---|
| Process cycle time | Document manually | 40-60% reduction | Workflow execution logs |
| Error rate in outputs | Track manually | Below defined threshold | Automated QA checks |
| Throughput capacity | Measured workload | 2x-5x increase | Pipeline throughput metrics |
| Operational cost per unit | Finance records | Reduction tracked quarterly | Cost allocation tags |
The MLOps monitoring framework using Prometheus and Grafana gives you the technical side of this validation. But you need to connect those technical signals to business outcomes for your validation to be credible to stakeholders outside the engineering team.
For guidance on AI model training quality metrics that feed into your validation process, that resource covers data-side measurement in detail.
Start your validation process with a 30-day post-deployment review. Compare baseline metrics to current performance across every major KPI. Use those findings to identify where the infrastructure is delivering expected results and where configuration adjustments are needed. Successful scalable AI systems treat validation as a continuous process, not a one-time gate.
Our perspective: What most guides miss about automation infrastructure
Most step-by-step infrastructure guides do a reasonable job covering the technical build sequence. Where they consistently fall short is in the operational and organizational realities that determine whether infrastructure actually succeeds in production.
The biggest gap we see is cross-functional alignment. Engineering teams can build technically excellent infrastructure that fails to deliver business value because the workflows it automates were never properly mapped to real business requirements. Automation built on top of broken processes does not fix those processes. It accelerates them. Getting business stakeholders, operations leads, and technical architects into the same room before the build starts is not a soft skill. It is an infrastructure requirement.
Observability is the second area where organizations consistently underinvest. Teams deploy monitoring dashboards and believe they have visibility. But true observability means you can explain why any given output looks the way it does, trace it back through every transformation in your pipeline, and reconstruct the exact state of your system at any point in time. Most deployments do not reach that standard.
We also believe that conventional wisdom about automation infrastructure leads teams to prioritize speed of deployment over resilience of design. Shipping fast to a fragile architecture is not progress. It is technical debt accrued at scale. The enterprise automation strategies that produce durable results are built on verified components, documented recovery processes, and the patience to test each layer before connecting the next.
Prioritize transparency in your stack. Every tool you select, every workflow you automate, and every metric you track should be explainable to any stakeholder in plain language. Opacity in automation infrastructure is a risk. It breeds distrust, slows adoption, and makes it nearly impossible to diagnose failures before they compound.
Connect with advanced automation solutions
Building the right infrastructure is a significant investment of time, expertise, and tooling. You do not have to figure it out from scratch.

At Starks Global Group, we have built verified automation blueprints designed specifically for organizations ready to deploy scalable, AI-driven systems. Our automation infrastructure platform provides structured architecture guidance, tested tool stacks, and deployment frameworks that eliminate the guesswork. Explore our automation tools marketplace for a curated set of verified tools aligned to each infrastructure layer. If your organization is ready to deploy immediately, our AI chatbot sales system blueprint shows exactly how production-grade automation is assembled and deployed in a real business context. We test every recommendation before we share it.
Frequently asked questions
What are the main layers of an AI automation infrastructure?
The four main layers are infrastructure foundation, model serving, application services, and client integration, each serving a distinct function in the overall system.
What tools are essential for building scalable automation infrastructure?
Core tools include Docker for containerization, CI/CD pipeline stages for automated deployment, plus storage systems and monitoring software such as Prometheus and Grafana.
How can I monitor and validate my automation infrastructure?
Use Prometheus and Grafana for technical monitoring, and pair those metrics with business KPIs to confirm that the infrastructure is delivering operational value after deployment.
What problems commonly arise during automation infrastructure setup?
The most frequent issues include missing incident classification, undefined rollback rules, and incomplete observability coverage, all of which slow recovery time when failures occur.